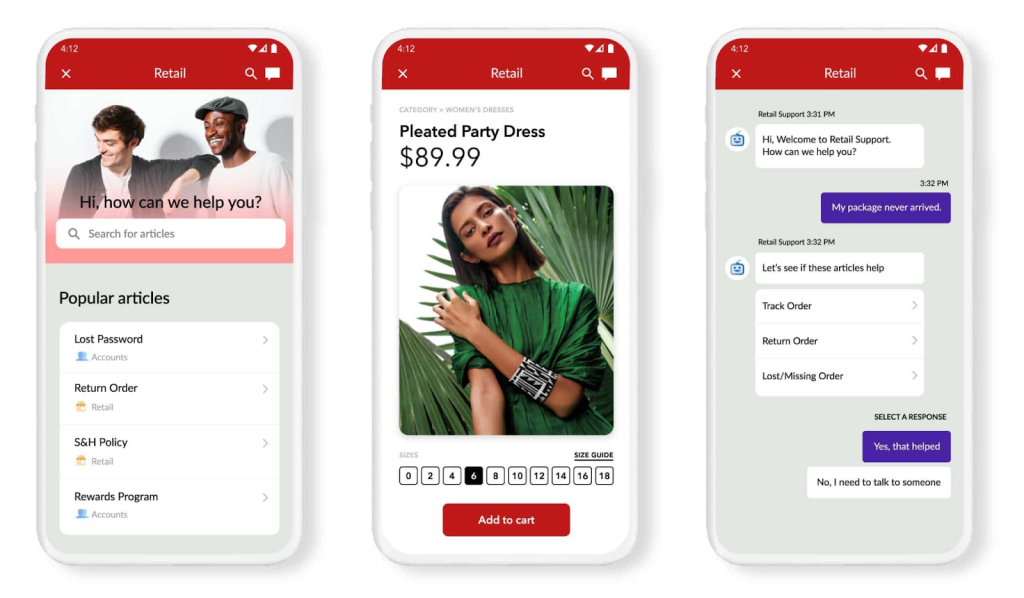
Providing fast and frictionless support for customer issues is essential for ensuring service excellence. Thus, it is critical to assign issues to appropriate agents and teams (or bots), while ensuring optimal resource utilization. The success of all downstream actions are based on the correct assignment of the ticket to the right agent or team. If the ticket is assigned incorrectly, it can create confusion within the team, delay the customer’s resolution and create a poor customer experience.
Just think of the last time you had to be transferred to multiple agents and the associated frustration for comparison sake.

Also, manual issue categorization is mundane for the agent and expensive for the organization (see below). Multiple-choice systems that provide the user with options to choose the related category is a better option, but not altogether useful. This is because new users who have never used the service before may be uninformed about the related category or department. Also, users do not want to fill out long ticket forms that are needed to identify the issue with a higher level of accuracy.
Alternatively, our recommended method provides smart classification without any complicated forms. It reduces manual effort, eliminates the risk of human triaging errors — while ensuring high levels of service and improved end-user satisfaction.
Current Industry Practices
1. In many organizations, the assignment of issues to the appropriate team or agent is still done manually. Especially at large organizations, manual assignment is not suitable because it is time consuming and requires extensive human bandwidth. It requires training for the personnel — and even then, it is prone to human errors. This leads to resources being wasted due to ineffective assignment as a result of incorrect manual classification. Additionally, manual assignment results in a longer response time, which results in end-user dissatisfaction.
2. Another approach that organizations take is the keyword-based automation approach. Here, organizations create a fixed list of keywords that map to different sets of issues, and then use that map for assignment logic. This requires the keyword set to be curated frequently: a very slow and resource intensive process that is never exhaustive. It needs to be kept updated to be in sync with business changes. Additionally, setting up and managing this list for every language is laborious.This method cannot handle synonyms, abbreviations or slang, spelling mistakes, or typing errors by the end user.
3. Multiple-choice systems (IVR type systems) ask the end user to select the related pre-defined issue category. These systems are not useful because users often do not have sufficient knowledge of the relevant categories — and this list is quite limited as you can only offer a handful of issue types to choose from. It is very irritating for the user to go through the multilayered flow just to identify the problem.
As evident from above, the current approaches to solving the classification problem are inadequate, resource-intensive and non-scalable.
We needed a product that could remove the burden of classification from agents and let them deal only with issues that are complex and require human intervention.
Primarily, we recognized that:

Therefore, we determined the answer to these observations to be an AI-enabled solution that can classify issues automatically and cost-effectively — a solution that works at scale, is customizable for the organization, and one that evolves over time.
Why AI-powered issue classification is better
We wanted to build a classification engine that could apply Machine Learning and AI algorithms to accurately predict the category of an incoming issue, and then allow our routing engine to assign the categorized issue to a relevant agent or a bot. The engine learns about the different categories of issues through a process called supervised learning aided with NLP algorithms.
To train the engine, a customer support supervisor or administrator needs to feed a bunch of sample issues from the existing ticketing system and specify the associated category. For the classification to be accurate, a minimum number of sample issues must be provided for every category.
This process can be repeated and the engine can be taught to identify issues across multiple categories. Once the data and respective categories have been fed into the engine, the machine training can start. Once the training has been completed, the admin will be given feedback about the engine performance, the level of accuracy reached, and whether more data will be required to improve accuracy.
Once the admin has enough confidence in the accuracy of the engine, it can be turned on to predict the category of incoming issues.
Furthermore, the admin should be able to view analytics about the engine’s performance and accuracy, e.g. the number of issues categorized correctly and average accuracy of those categorizations. This can be further improved by routinely incorporating agent feedback on the issue categorization. The engine should also be enabled or disabled by the admin as needed.
Transparency is an important element as well, so the engine should at every step make an effort to disclose its activities and performance so that it can be treated as an intelligent assistant and not an unpredictable black box.
Problems with Generic AI systems
Using any generic AI system’s algorithm for this specific problem has constraints. Most of the algorithms available off-the-shelf have been programmed to solve any general purpose supervised machine learning classification task. Due to this, these algorithms fail to account for certain nuances that are very specific to particular verticals.
The data scientists at Helpshift have determined from internal research that they are able to achieve better results by modifying these general purpose algorithms in order to cater to the support domain specifically. Helpshift is largely an in-app platform and the idea of sending messages from a mobile phone carries some inherent issues:
- Most of the issues received on our platform are short texts (2-3 sentences max). They also lack a proper grammatical structure and the context is often incomplete.
- End users sending messages from mobile devices involuntarily type as if they are casually texting and hence tend to use abridged and abbreviated forms of words. They also make more mistakes while typing that result in misspellings that are important to the context of the message.
- Every vertical or domain has its own vocabulary and people seldom use irrelevant words while talking to support. A generic model tends to use a larger vocabulary that adds noise to the algorithm.

The Helpshift way: in-house AI-Powered Issue Classification
Having discovered these problems, our team of data scientists decided to build an in-house AI engine that is powerful and tailor-made to our needs. The state-of-the-art algorithms that power SensAI Predict have their roots in semantics and contextual similarity. The algorithms are capable of handling semantically similar words, short-length texts and even common spelling mistakes. We use an ensemble of sophisticated machine learning algorithms rooted in core NLP.
The team has developed a novel method of issue classification that uses the combination of Contextual Similarity, Convex Geometry and Bayesian Probability to generate vectors in semantic spaces. In comparison to the traditional methods that use statistical significance or rule-based labelling strategies, our method uses Contextual Similarity as the basis for classification.
With our native AI, we can now build domain-specific models that make label predictions with high levels of accuracy. Using our integrated feedback mechanism, agents and admins can provide feedback on incorrect predictions. The model penalizes incorrect predictions and boosts the scores of correct predictions in daily batch updates.
Thus the algorithm continuously learns from the feedback and improves the prediction quality over time as a result.

AI designed for non-technical users (Admins):
The target user for this product is a customer support admin who manages the workflows and operations for the support team. These admins are generally non-technical users.
The major challenge for our team was to design the feature in such a way that there is no coding necessary, no data scientist required and no integrations.
We extracted the complexities of AI and modeled them into user-friendly workflows. Our priorities were as follows:
- Admins should be able to self-serve through the dashboard directly.
- Accuracy and other metrics should be available in the dashboard to determine the efficacy of the models (and improve them as required).
- The system should be designed to handle continuous changes happening in the organization so admins can easily modify the model when required.
For any machine learning system, the feedback mechanism is of utmost importance to improve the system over time. Apart from admins improving the models by retraining with new data, agents can also give feedback to the category labels that are added to the issues. It is crucial for agents to have easy access and a simple interface to provide the feedback when the labels are not correct. That’s why Predict feedback can be provided by a single click. Agents can also provide the correct label for the issue, which will also be accounted for by the algorithm.
As an end-to-end customer support platform, we already have strong workflow management systems in place. With the introduction of AI into our platform, we now leverage these capabilities to build a seamless and extensible experience for the admins.
Helpshift Predict can be utilized across our system right from the assignment engine, to sending auto-replies to users based on the specific labels, to assigning issues to a bot. This makes the AI products an integral part of the Helpshift platform and creates a unique environment for admins to explore all the capabilities right through the dashboard itself.
Salient Benefits:

- Turnkey Solution: This is the key benefit of designing an integrated system, as this accessibility means no data scientist is required for customizing or configuring the system for the domain. Any admin with basic operational knowledge of the system can design, evaluate, and modify the Predict engine to best suit the organizational needs.
- Improved accuracy: Based on existing customer data, Helsphift Predict is able to deliver an average accuracy of over 80 percent, and the perceived accuracy even higher than the calculated accuracy.
- Continuous learning: There’s an easy and integrated feedback mechanism to continuously improve the accuracy of the classification algorithm.
- Multi-Language Support: This feature is available for 19 languages including English, Arabic, Chinese, Korean, French, German, Italian, Japanese, Portuguese, Russian and Spanish.
Learn more about Helpshift’s philosophy and robust AI and bot capabilities here or go ahead and request a demo with our sales team to get started!